maplearn.ml package¶
Machine Learning¶
What is Machine Learning?
From Wikipedia: “Machine learning algorithms build a mathematical model based on sample data, known as “training data”, in order to make predictions or decisions without being explicitly programmed to perform the task.”

So, we use Machine Learning to predict results about unknown data:
- Is this new email a spam?
- Is this an image of a cat or a dog?
- How many people are going to buy my new product?
- Applications are infinite…
To answer these questions, we will use mathematical models (the cloud in the above figure) that need to be trained (or fitted) prior to make predictions.
What to predict?
Depending on the nature of the values to be predicted, we will talk about:
- classification when the values are discrete (also called categorical)
- regression when the values are continuous
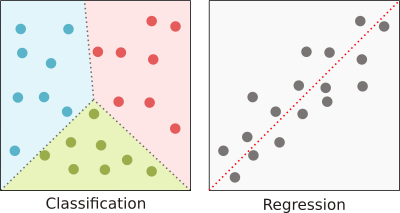
Classification and regression both needs some samples for training, they belong to supervised learning. If you do not have samples, then you should consider unsupervised classification, also called clustering.
Note
On the other hand, a regression can’t be made without samples.
Maplearn: machine Learning modules
In maplearn, machine learning is empowered by scikit-learn. One reason is its great documentation. Have a look to go further.
Maplearn provides 3 modules corresponding to each of these tasks:
- Classification
- Clustering
- Regression
Two other modules are linked to these tasks:
- Confusion: confusion matrix (used to evaluate classifications)
- Distance: computes distance using different formulas
Another task that can accomplish machine learning is to reduce the number of dimensions (also called features)
- Reduction: dimensionnality reduction
The last submodule is needed for programmation but should not be used itself:
- Machine: abstract class of a machine learning processor, one or more algorithms can be applied
Submodules¶
maplearn.ml.classification module¶
Classification
Classification methods are used to generate a map with each pixel assigned to a class based on its multispectral composition. The classes are determined based on the spectral composition of training areas defined by the user.
Classification is supervised and need samples to fit on. The output will be be a matrix with integer values.
- Example:
>>> from maplearn.datahandler.loader import Loader >>> from maplearn.datahandler.packdata import PackData >>> loader = Loader('iris') >>> data = PackData(X=loader.X, Y=loader.Y, data=loader.aData) >>> lst_algos = ['knn', 'lda', 'rforest'] >>> dir_out = os.path.join('maplean_path', 'tmp') >>> clf = Classification(data=data, dirOut=dir_out, algorithm=lst_algos) >>> clf.run()
-
class
maplearn.ml.classification.Classification(data=None, algorithm=None, **kwargs)¶ Bases:
maplearn.ml.machine.MachineApply supervised classification onto a dataset:
- samples needed for fitting
- data to predict
- Args:
- data (PackData): data to play with
- algorithm (list or str): name of an algorithm or list of algorithm(s)
- **kwargs: other parameters like kfold
-
export_tree(out_file=None)¶ Exports a decision tree
- Args:
- out_file (str): path to the output file
-
fit_1(algo, verbose=True)¶ Fits a classifier using cross-validation
- Arg:
- algo (str): name of the classifier
-
load(data)¶ Loads necessary data for supervised classification:
- samples (X and Y): necessary for fitting
- other (unknwon) data to predict, after fitting
- Args:
- data (PackData)
-
optimize(algo)¶ Optimize parameters of a classifier
- Args:
- algo (str): name of the classifier to use
-
predict_1(algo, proba=True, verbose=True)¶ Predict classes using a fitted algorithm applied to unknown data
- Args:
- algo (str): name of the algorithme to apply
- proba (bool): should probabilities be added to result
-
run(predict=False, verbose=True)¶ Applies every classifiers specified in ‘algorithm’ property
- Args:
- predict (bool): should be the classifier only fitted or also used to predict?
-
maplearn.ml.classification.lcs_kernel(x, y)¶ Custom kernel based on LCS (Longest Common Substring)
- Args:
- x and y (matrices)
- Returns:
- matrix of float values
-
maplearn.ml.classification.skreport_md(report)¶ Convert a classification report given by scikit-learn into a markdown table TODO: replaced by a pandas dataframe
- Arg:
- report (str): classification report
- Returns:
- str_table: a table formatted as markdown
-
maplearn.ml.classification.svm_kernel(x, y)¶ Custom Kernel based on DTW
- Args:
- x and y (matrices)
- Returns:
- matrix of float values
maplearn.ml.clustering module¶
Clustering (unsupervised classification)
A clustering algorithm groups the given samples, each represented as a vector x in the N-dimensional feature space, into a set of clusters according to their spatial distribution in the N-D space. Clustering is an unsupervised classification as no a priori knowledge (such as samples of known classes) is assumed to be available.
Clustering is unsupervised and does not need samples for fitting. The output will be a matrix with integer values.
- Example:
>>> from maplearn.datahandler.loader import Loader >>> from maplearn.datahandler.packdata import PackData >>> loader = Loader('iris') >>> data = PackData(X=loader.X, Y=loader.Y, data=loader.aData) >>> lst_algos = ['mkmeans', 'birch'] >>> dir_out = os.path.join('maplean_path', 'tmp') >>> cls = Clustering(data=data, dirOut=dir_out, algorithm='mkmeans') >>> cls.run()
-
class
maplearn.ml.clustering.Clustering(data=None, algorithm=None, **kwargs)¶ Bases:
maplearn.ml.machine.MachineApply one or several methods of clustering onto a dataset
- Args:
- data (PackData): dataset to play with
- algorithm (str or list): name of algorithm(s) to use
- **kwargs: more parameters about clustering. The ‘metric’ to use, the number of clusters expected (‘n_clusters’)
-
fit_1(algo, verbose=True)¶ Fits one clustering algorithm
- Arg:
- algo (str): name of the algorithm to fit
-
load(data)¶ Loads necessary data for clustering: no samples are needed.
- Arg:
- data (PackData): data to play with
-
predict_1(algo, export=False, verbose=True)¶ Makes clustering prediction using one algorithme
- Args:
- algo (str): name of the algorithm to use
- export (bool): should the result be exported?
maplearn.ml.confusion module¶
Confusion matrix
A confusion matrix, also known as an error matrix, is a specific table layout that allows visualization of the performance of a classificarion algorithm (see ‘classification’ class).
Each column of the matrix represents the instances in a predicted class while each row represents the instances in an actual class. The name stems from the fact that it makes it easy to see if the system is confusing two classes.
- Example:
>>> import numpy as np >>> # creates 2 vectors representing labels >>> y_true = np.random.randint(0, 15, 100) >>> y_pred = np.random.randint(0, 15, 100) >>> cm = Confusion(y_true, y_pred) >>> cm.calcul_matrice() >>> cm.calcul_kappa() >>> print(cm)
-
class
maplearn.ml.confusion.Confusion(y_sample, y_predit, fTxt=None, fPlot=None)¶ Bases:
objectComputes confusion matrix based on 2 vectors of labels:
- labels of known samples
- predicted labels
- Args:
- y_sample (vector): vector with known labels
- y_predit (vector): vector with predicted labels
- fTxt (str): path to the text file to write confusion matrix into
- fPlot (str): id. with chart
- Attributes:
- y_sample (vector): true labels (ground data)
- y_predit (vector): corresponding predicted labels
- cm (matrix): confusion matrix filled with integer values
- kappa (float): kappa index
- score (float): precision score
- TODO:
- y_sample and y_predit should be renamed y_true and y_pred
-
calcul_matrice()¶ Computes a confusion matrix and display the result
- Returns:
- matrix (integer): confusion matrix
- float: kappa index
-
export(fTxt=None, fPlot=None, title=None)¶ Saves confusion matrix in:
- a text file
- a graphic file
- Args:
- fTxt (str): path to the output text file
- fPlot (str): path to the output graphic file
- title (str): title of the chart
-
kappa¶ Computes kappa index based on 2 vectors
- Returns:
- float: kappa index
-
maplearn.ml.confusion.confusion_cl(cm, labels, os1, os2)¶ Computes confusion between 2 given classes (expressed in percentage) based on a confusion matrix
- Args:
- cm (matrix): confusion matrix
- labels (array): vector of labels
- os1 and os2 (int): codes of th classes
- Returns:
- float: confusion percentage between 2 classes
maplearn.ml.distance module¶
Distance
Computes pairwise distance between 2 matrices, using several metric (euclidean is the default)
- Example:
>>> import numpy as np >>> y1 = np.random.random(50) >>> y2 = np.random.random(50) >>> dist = Distance(y1, y2) >>> dist.run()
-
class
maplearn.ml.distance.Distance(x=None, y=None)¶ Bases:
objectComputes pairwise distance between 2 matrices (x and y)
- Args:
- x (matrix)
- y (matrix)
-
compare(x=None, y=None, methods=[])¶ Compare pairwise distances got with different metrics
- Args:
- x and y (matrices)
- methods (list): list of metrics used to compute pairwise distance. if empty, every available metrics will be compared
-
dtw(x=None, y=None)¶ Dynamic Time-Warping distance
-
lcs(x=None, y=None, eps=10, delta=3)¶ Distance based on Longest Common Subsequence
-
run(x=None, y=None, meth='euclidean')¶ Distance calculation according to a specified method
- Args:
- x (matrix)
- y (matrix)
- meth (str): name of the metric distance to use
- Returns:
- matrix of pairwise distance values
-
simplex(x=None, y=None, sigma=50)¶ Simplex distance
maplearn.ml.reduction module¶
Dimensionnality reduction
The number of dimensions are reduced by selecting some of the features (like in kbest approach) or transforming them (like in PCA…). This reduction is applied to samples and the data to predict in further step.
Several approaches are available, which are listed in the class attribute “ALG_ALGOS”.
-
class
maplearn.ml.reduction.Reduction(data=None, algorithm=None, **kwargs)¶ Bases:
maplearn.ml.machine.MachineThis class reduces the number of dimensions by selecting some of the features or transforming them (like in PCA…). This reduction is applied to samples and the data to predict in further step.
- Args:
- data (PackData): dataset to reduced
- algorithm (list): list of algorithm(s) to apply on dataset
- **kwargs: parameters about the reduction (numberof components) or the dataset (like features)
- Attributes:
- attributes inherited from Machine classe
- ncomp (int): number of components expected
-
fit_1(algo)¶ Fits one reduction algorithm to the dataset
- Args:
- algo (str): name of the algorithm to fit
-
load(data)¶ Loads dataset to reduce
- Args:
- data (PackData): dataset to load
-
predict_1(algo)¶ Applies chosen way of reduction to the dataset
- Args:
- algo (str): name of the algorithm to apply
-
run(predict=True, ncomp=None)¶ Executes reduction of dimensions (fits and applies)
- Args:
- predict (bool): should apply the reduction or just fit the
- algorithm ?
- ncomp (int): number of dimensions expected
- Returns:
- array: reduced features data
- array: reduced samples features
- list: liste of features
maplearn.ml.regression module¶
Regression
In statistical modeling, regression analysis is a statistical process for estimating the relationships among variables. It includes many techniques for modeling and analyzing several variables, when the focus is on the relationship between a dependent variable and one or more independent variables.
Regression analysis is supervised and need samples for fitting. The output will be a matrix with float values.
Example:
>>> from maplearn.datahandler.loader import Loader
>>> from maplearn.datahandler.packdata import PackData
>>> from maplearn.ml.regression import Regression
>>> loader = Loader('boston')
>>> data = PackData(X=loader.X, Y=loader.Y, data=loader.aData)
>>> reg = Regression(data=data, dirOut=os.path.join('maplearn_path', 'tmp'))
>>> reg.fit_1(self.__algo)
-
class
maplearn.ml.regression.Regression(data=None, algorithm=None, **kwargs)¶ Bases:
maplearn.ml.machine.MachineApplies regression using 1 or several algorithm(s) onto a specified dataset
- Args:
- data (PackData): dataset to play with
- algorithm (list or str): name of the algorithm(s) to use
- **kwargs: more parameters like k-fold
Attributes and properties are inherited from Machine class
-
fit_1(algo)¶ Fits one regression algorithm
- Arg:
- algo (str): name of the algorithm to fit
-
load(data)¶ Loads necessary data for regression, with samples (labels are float values).
- Arg:
- data (PackData): data to play with
- Returns:
- int: did data load correctly (returns 0) or not (<> 0) ?
- TODO:
- checks a few things when loading…
-
optimize(algo)¶ Optimize parameters of a regression algorithm
- Args:
- algo (str): name of the regressor to use
-
predict_1(algo, proba=False)¶ Predicts Y using one regressor (specified by algo)
Args:
- algo (str): key of the regressor to use
- proba (bool): should probabilities (if available) given by algorithm be added to result?
-
run(predict=False)¶ Applies every regressors specified in ‘algorithm’ property
- Args:
- predict (bool): should be the regressor only fitted or also used
- to predict?
maplearn.ml.machine module¶
Machine Learning class
Fits and predict result using one or several machine learning algorithm(s).
This is an abstract class that should not be used directly. Use instead one one of the these classes:
- Classification: supervised classification
- Clustering: unsupervised classification
- Regression: regression
- Reduction: to reduce dimensions of a dataset
-
class
maplearn.ml.machine.Machine(data=None, algorithm=None, **kwargs)¶ Bases:
objectClass to apply one or several machine learning algorithm(s) on a given dataset.
Args:
- data (PackData): data to use with machine learning algorithm(s)
- algorithm (list or str): algorithm(s) to use
Attributes:
- algo (str): key code of the currently used algorithm
- result (dataframe): result(s) predicted by algorithm(s)
- proba (dataframe): probabilities produced by some algorithm(s)
Properties:
- algorithm (list): machine learning algorithm(s) to use
-
ALL_ALGOS= {}¶
-
algorithm¶ Gets list of algorithm that will be used when running the class
-
fit_1(algo)¶ Fits an algorithm to dataset
-
load(data)¶ Loads necessary data to machine learning algorithm(s)
Args:
- data (PackData): dataset used by machine learning algorithm(s)
-
predict_1(algo, export=False)¶ Predict a result using a given algorithm
Args:
- algo (str): key name identifying the algorithm to use
- export (bool): should the algorithm be used to predict results
-
run(predict=False)¶ Apply machine learning task(s) using every specified algorithm(s)
Args:
- predict (boolean): should machine learning algorithm(s) be used to predict results (or just be fitted to samples) ?